HISM(Hierarchical Instanced Static Mesh)是如何工作的
右击原图
虚幻中植被的方案除掉自然淘汰的procedual foliage tool,大概分为Foliage和GrassType两种,其中GrassType的原理比较简单,基本观察下就能猜到原理。相对来说Foliage更加黑盒, 抓帧的时候经常会觉得植被draw call数量过多,LOD分布奇怪,合批不合理等问题。本文通过追踪代码分析HISM的构建、剔除、合批过程,纯个人理解,为保持简洁省去部分分支,有不足之处还请指正。
·基本划分
按照更新的频率可以分为三个部分:
·构建Cluster Tree
首先初始化的时候从控制台获取一堆变量,其中比较重要的是CVarMinVertsToSplitNode,这个参数既会影响cluster里植被的数量,也会影响到最后合批的时候每级lod的instance数量。
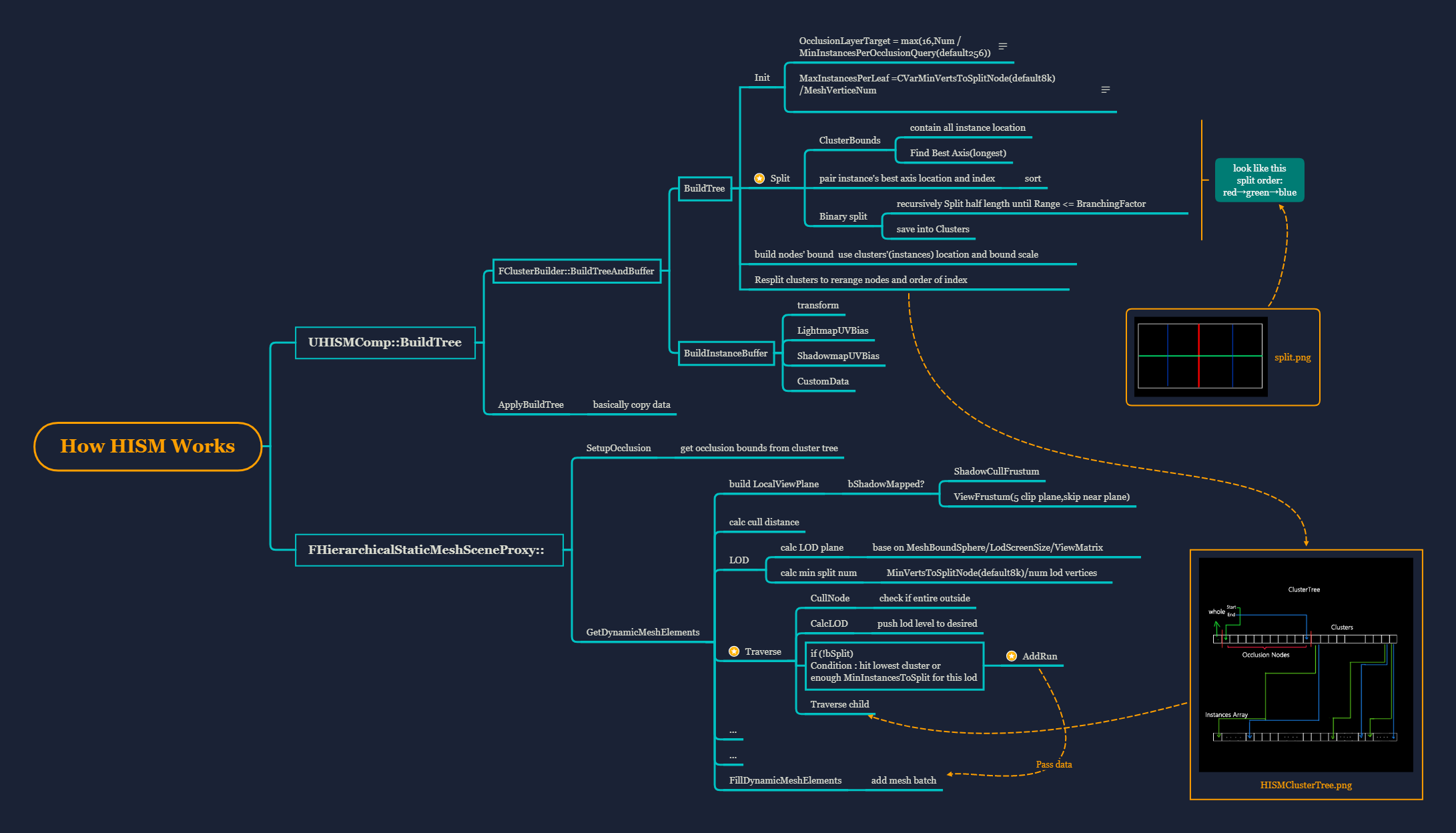
然后开始对全部instance的位置构建一个AABB的包裹框,寻找最长的轴进行一次切分,切分后对本次切分的数据进行重新排序,再对左右两组数据继续递归切分。 直到单组内数量少于上述变量除以模型顶点数决定的上限。切分过程类似下图中红→绿→蓝的顺序:
在得到一个个最基础的cluster后,我们再按照上述的方法对cluster进行一次递归的split,区别是之前的基础单位是单个instance,这次是cluster。 被整合起来的cluster组叫做occlusion nodes。引擎实际切分后bound的可视化:

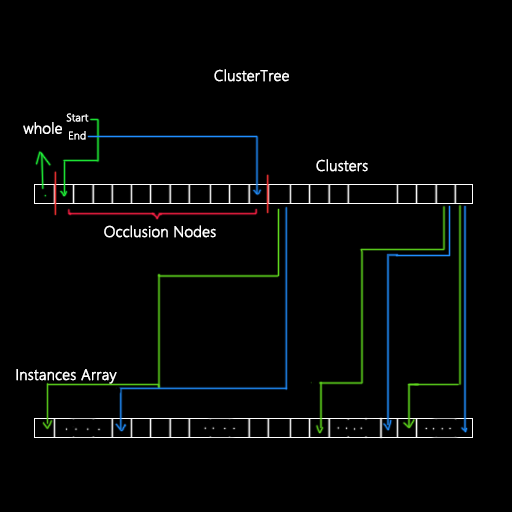
完成上述过程后得到一个树结构和对应重新排序的instance数组,对应关系如下图,ClusterTree数组中的0元素包含全部的Occlusion Nodes, 各个Occlusion Node又指向自身包含的clusters的起止位置。每一级又都有自己的bound和对应instance array的起止位置。
·Setup Occlusion
这部分主要就是SceneProxy对Component上传过来的cluster tree解包,得到occlusion bounds,因为不需要每帧更新被抽了出来。
·剔除/LOD/合批
首先构建视平面,有动态阴影就从ShadowCullFrustum构建,没有就从视锥。然后计算剔除距离,受编辑器参数控制。
各级LOD的切换距离由3个因素决定,Mesh的bound大小(这里是平均缩放大小,不是单个),各级LOD设置的screen size和视锥的matrix。
有了上述的信息之后,就可以开始遍历cluster tree整合出真正绘制需要的数据:
观察发现跳出大致有两种情况:
上面每次满足条件跳出都添加了一次绘制需要的数据,在后续FillDynamicMeshElements时直接添加到了Mesh Batch里。
·结论
了解HISM的工作原理解决了我之前比较困扰的几个问题:
Q:为什么通常近处的draw call会更细碎,数量更多,远处合批力度相对更大?
Q:为什么很多草绘制的是同一级LOD,却被分成了好几次draw call?
Q:为什么植被LOD要在效果满足的情况下尽早切换到Billboard?