B-Spline/Catmull-Rom Bicubic Filtering
左→右:Point \ Bi-Linear \ B-Spline \ Catmull-Rom 9 Samples \ Catmull-Rom 5 Samples
本文是对Bicubic Filtering in Fewer Taps一文的说明、补充。
·原理介绍
常见贴图采样的Filter有Point、Bi-Linear、Tri-Linear等,其中Bi-Linear又可以当作双轴,每轴两次(数量)采样的一次(指数)滤波,这里的一次指的是采样权重函数里x的最大指数。
//采样权重函数
y = 1-x
w0 = 1-x;
w1 = x;
//考虑单轴向时
S = S0*w0 + S1*w1
以此类推,Bi-Cubic就是双轴,每轴四次(数量)采样的三次(指数)滤波。
//采样权重函数
y = ax^3 + bx^2 + cx + d;
float2 w0 = //...
float2 w1 = //...
float2 w2 = //...
float2 w3 = //...
//考虑单轴向时
S = S0*w0 + S1*w1 + S2*w2 + S3*w3;
本文将介绍两种三次函数B-Spline和Catmull-Rom,这里先忽略函数本身,专注在函数的采样过程上。
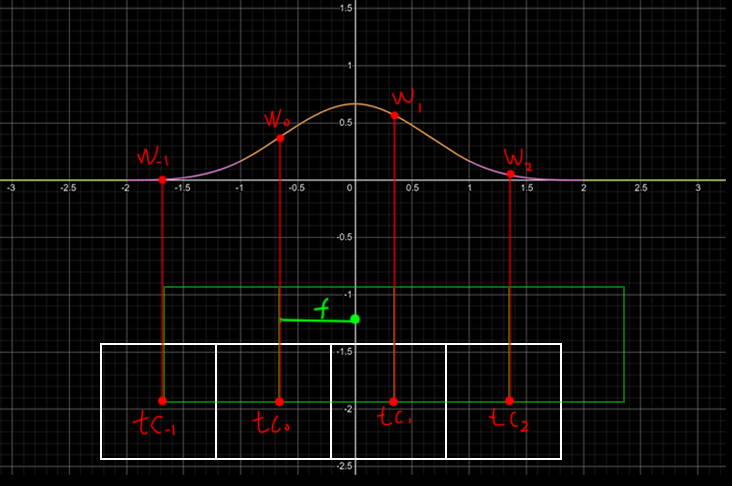
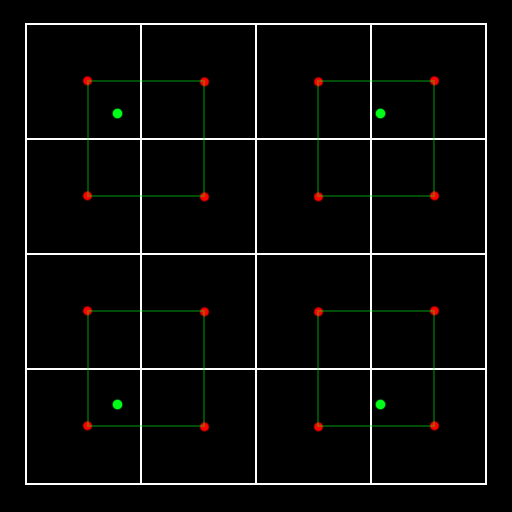
现在先考虑单轴,上图的绿色点为采样点,以采样点为中心展开权重函数。上图白色的格子是贴图的纹素,红色点为纹素中心。 这里把我的采样点'下落'到最近的纹素中心。下面代码中括号里的减0.5非常重要,这保证了f的范围落于0-1之间,整个采样点的范围活动在第二、三纹素之间(上图第二个绿色方格)。
float2 invTexSize = 1./texSize;
float2 iTc = uv*texSize;
//纹素的中心
float2 tc = floor( iTc - 0.5 ) + 0.5;
//f范围从0-1,落于上图第二个绿色方格中
float2 f = iTc - tc;
float2 f2 = f * f;
float2 f3 = f2 * f;
//用指定的曲线计算权重
float2 w0 = //...
float2 w1 = //...
float2 w2 = //...
float2 w3 = //...
根据上述的采样方法,可以得到x,y轴各4个的采样权重。组合成4x4共16个采样点的权重,继而对这些点进行采样配权得到最后的采样结果。
//get our texture coordinates
float2 tc0 = tc - 1;
float2 tc1 = tc;
float2 tc2 = tc + 1;
float2 tc3 = tc + 2;
//convert them to normalized coordinates
tc0 *= invTexSize;
tc1 *= invTexSize;
tc2 *= invTexSize;
tc3 *= invTexSize;
return
Texture2DSample( Tex2D, float2( tc0.x, tc0.y ) ) * w0.x * w0.y
+ Texture2DSample( Tex2D, float2( tc1.x, tc0.y ) ) * w1.x * w0.y
+ Texture2DSample( Tex2D, float2( tc2.x, tc0.y ) ) * w2.x * w0.y
+ Texture2DSample( Tex2D, float2( tc3.x, tc0.y ) ) * w3.x * w0.y
+ Texture2DSample( Tex2D, float2( tc0.x, tc1.y ) ) * w0.x * w1.y
+ Texture2DSample( Tex2D, float2( tc1.x, tc1.y ) ) * w1.x * w1.y
+ Texture2DSample( Tex2D, float2( tc2.x, tc1.y ) ) * w2.x * w1.y
+ Texture2DSample( Tex2D, float2( tc3.x, tc1.y ) ) * w3.x * w1.y
+ Texture2DSample( Tex2D, float2( tc0.x, tc2.y ) ) * w0.x * w2.y
+ Texture2DSample( Tex2D, float2( tc1.x, tc2.y ) ) * w1.x * w2.y
+ Texture2DSample( Tex2D, float2( tc2.x, tc2.y ) ) * w2.x * w2.y
+ Texture2DSample( Tex2D, float2( tc3.x, tc2.y ) ) * w3.x * w2.y
+ Texture2DSample( Tex2D, float2( tc0.x, tc3.y ) ) * w0.x * w3.y
+ Texture2DSample( Tex2D, float2( tc1.x, tc3.y ) ) * w1.x * w3.y
+ Texture2DSample( Tex2D, float2( tc2.x, tc3.y ) ) * w2.x * w3.y
+ Texture2DSample( Tex2D, float2( tc3.x, tc3.y ) ) * w3.x * w3.y;
这样就得到了一个Bi-Cubic Filter的采样结果。
·采样优化
上面的过程一共需要手动采样16次,借助硬件的Bi-Linear Filter,最理想的情况下可以把采样数降到4次。
首先,我们先专注在单轴相邻的两个纹素之间,从上诉代码中可以看到每行Sample都可以写成Texel * Weight的形式,因此我们可以把相邻纹素的和写成:

而我们对两个像素做线性插值时,插值的结果可以写成:
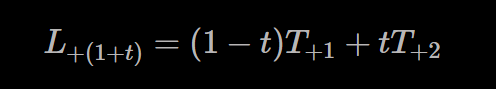
因为w1加w2并不一定会等于1,我们假设有个值s,使得s(w1+w2) = 1
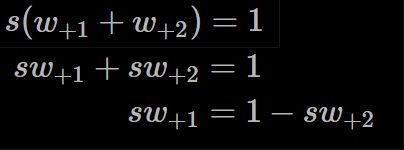
将最上面的等式乘s,再将上式代入
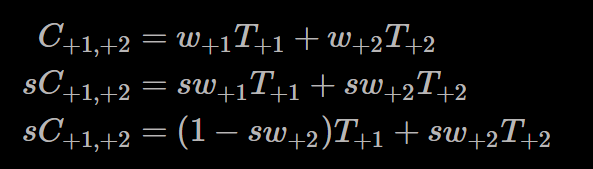
这里可以发现式子成了做线性插值的形式,令t=sW2代入上式,也就是将我们的采样点放在sW2的位置上:
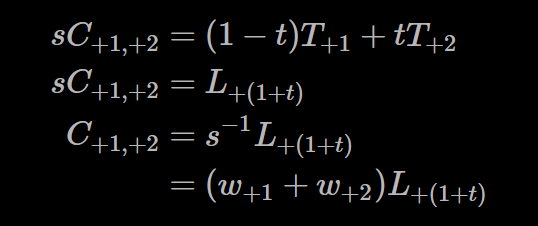
最后s被替换掉,采样权重和变成了权重和乘以线性插值的结果,这可能是近期见过最优美的算法了。
替换之后,原本16次的采样(红色点)变成了坐落在绿色区域里的4次采样(绿色点)。
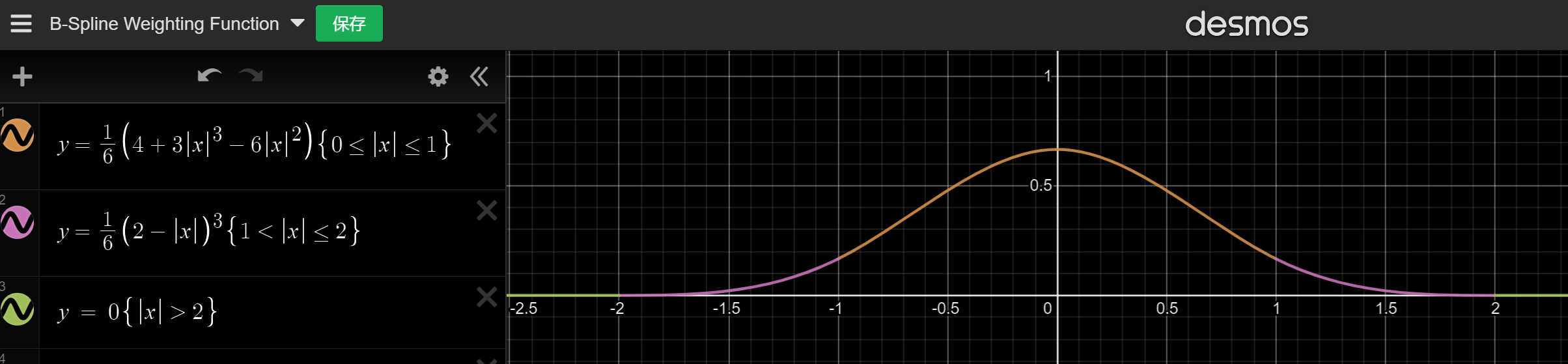
·B-Spline 权重函数
下面开始介绍第一种曲线B-Spline,是一个零点对称的多段函数。
结合上面的采样图可以找到4个采样点的位置:

因为之前我们保证了f属于0-1之间,因此这里的4个采样点都确保落在了某个区间的函数上,直接代入即可得到权重,继而进行上面的合并优化计算。
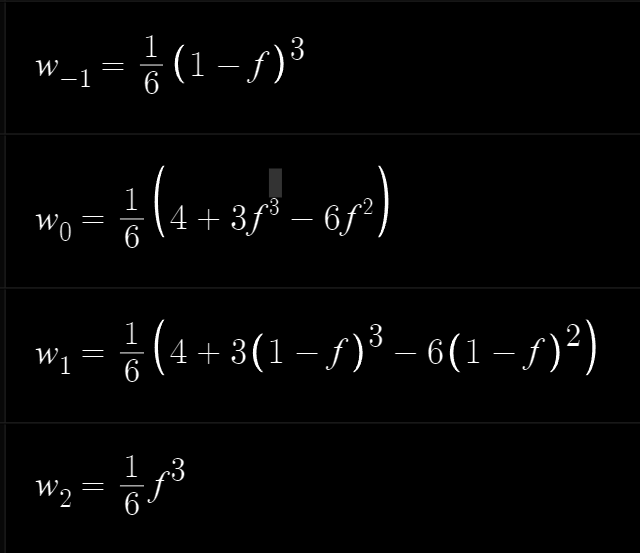
·Catmull-Rom 权重函数
Catmull-Rom的分段信息和B-Spline曲线一致,曲线走向如下:
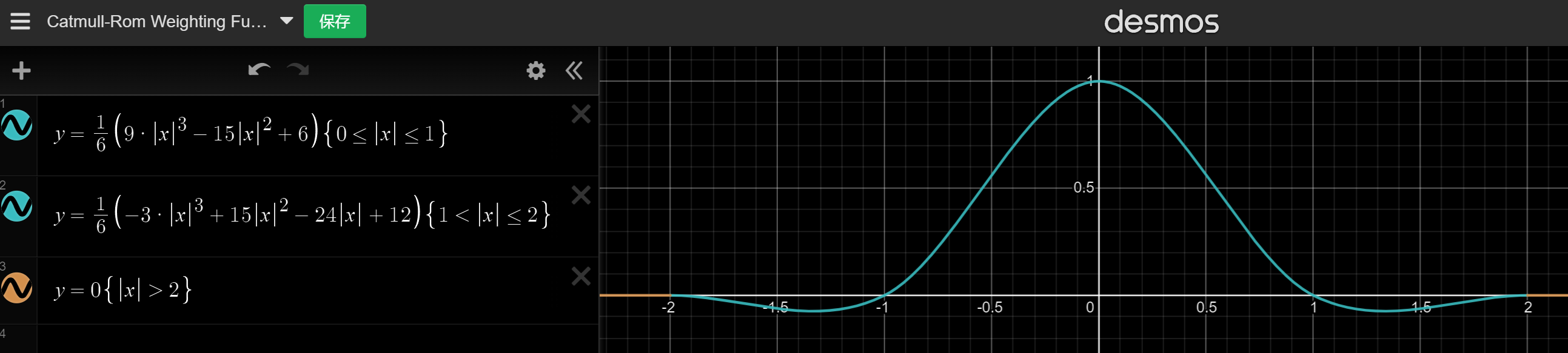
因此采样点区间也可以确定使用的函数
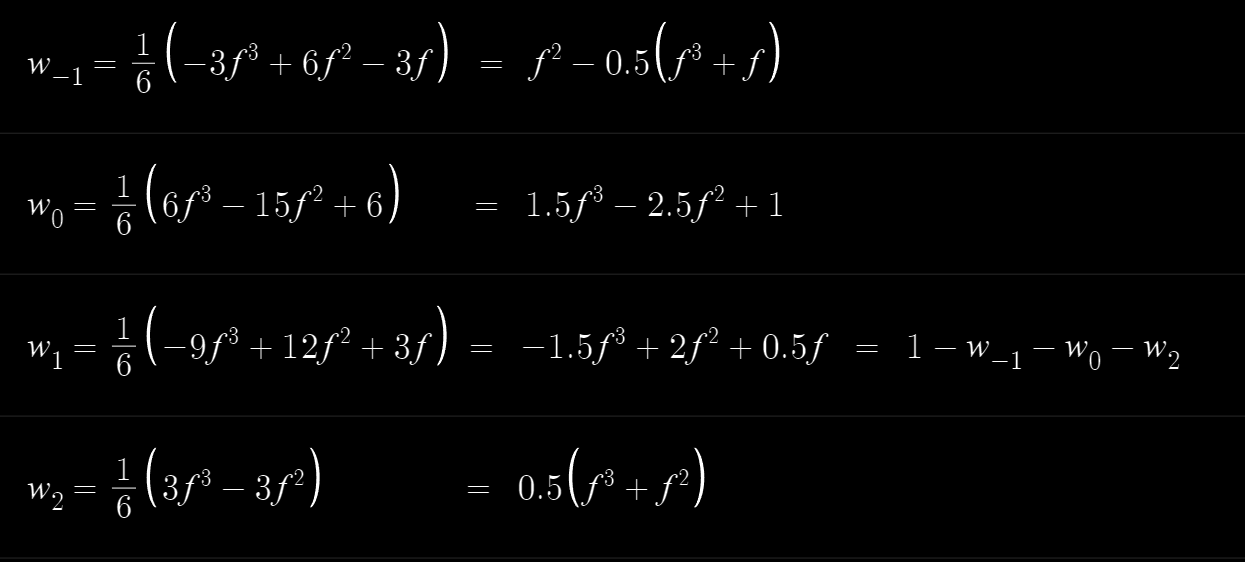
但是有一个重要的区别就是:x在1-2区间里有负数。采样的位置t = sW2,也就是W2/(W1+W2),在W1或者W2中有一个值小于0时,都会导致t的值大于1。而t大于1意味着我们没办法借助硬件的Bi-Linear Filter来进行采样了。
这样对于轴向上包含负数区域的相邻点,就无法进行合并,只能单独采样。重新构建我们的采样点分布如下:
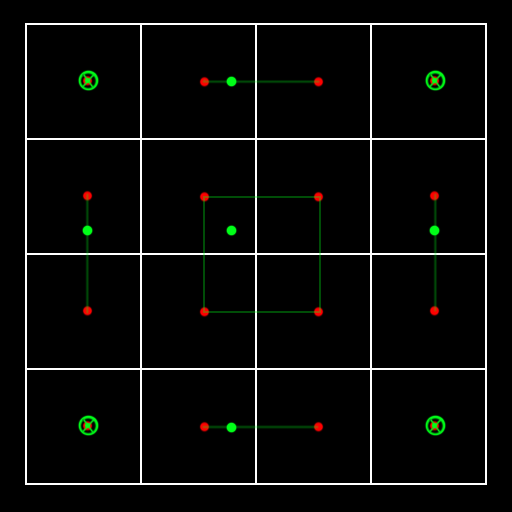
中间区域的4个点用上面的优化合并。4条边的中间两个点在作为函数负数区间的轴上直接舍弃,相当于在此轴上Point采样,而另一个轴向上正处于中间两个采样点的位置权重为正数,这样就规避了上面的问题。对于角上的4个点直接进行Point采样。这样一共需要1+4+4共9次采样。
//TextureSampling.ush l:164
// Reweight after removing the corners
float CornerWeights;
CornerWeights = Samples.Weight[0];
CornerWeights += Samples.Weight[1];
CornerWeights += Samples.Weight[2];
CornerWeights += Samples.Weight[3];
CornerWeights += Samples.Weight[4];
Samples.FinalMultiplier = 1 / CornerWeights;
最后,在虚幻引擎中很多用到Capmull-Rom算法的地方都去掉了角上的4个点(上图绿色叉点),对其他点加权后重新分配权重,这样只剩下5个采样,也是一种优化的方式。
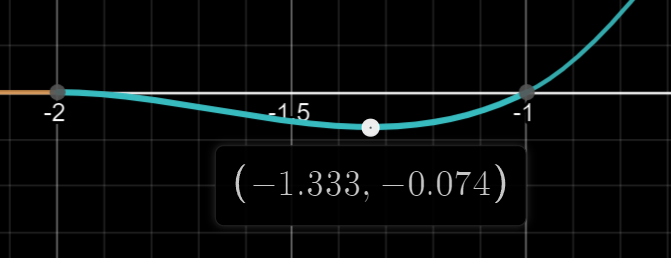
看下曲线在1-2最小值,之所以能忽略掉这4个点,是因为即使在极限值情况下4个点权重和也只有0.074*0.074*4 = 0.021904,占整体权重的比例非常小。